Hi everyone,
My storage pool has become degraded, and I’ve searched through other degradation discussions on the forum, but I’m not sure if they apply to my specific situation. I’m hoping someone can help me resolve this issue.
System Information:
Platform: Generic
Version: TrueNAS-SCALE-22.02.4
CPU: 12th Gen Intel(R) Core™ i5-12400
MotherBoard: ASUS PRIME Z690M-PLUS D4
HDD: WDC_WUH721818ALE6L4 18TB * 6
SSD: WD_BLACK SN750 SE 1TB * 2
Memory: Cuso 16G DDR4 2666MHz * 4
PowerSupply: Seasonic SS-350M1U
Error Message I’m Encountering:
CRITICAL
Pool main state is DEGRADED: One or more devices are faulted in response to persistent errors. Sufficient replicas exist for the pool to continue functioning in a degraded state.
The following devices are not healthy:
Disk WDC_WUH721818ALE6L4 4ZG4DU2V is FAULTED
Disk WDC_WUH721818ALE6L4 4ZG76JLV is FAULTED
Disk WDC_WUH721818ALE6L4 4ZG743KV is DEGRADED
2025-08-16 16:22:05 (Asia/Shanghai)
Additionally, I’ve noticed that since 2023, there have been continuous “ATA error count increased” errors appearing intermittently.
Console Output:
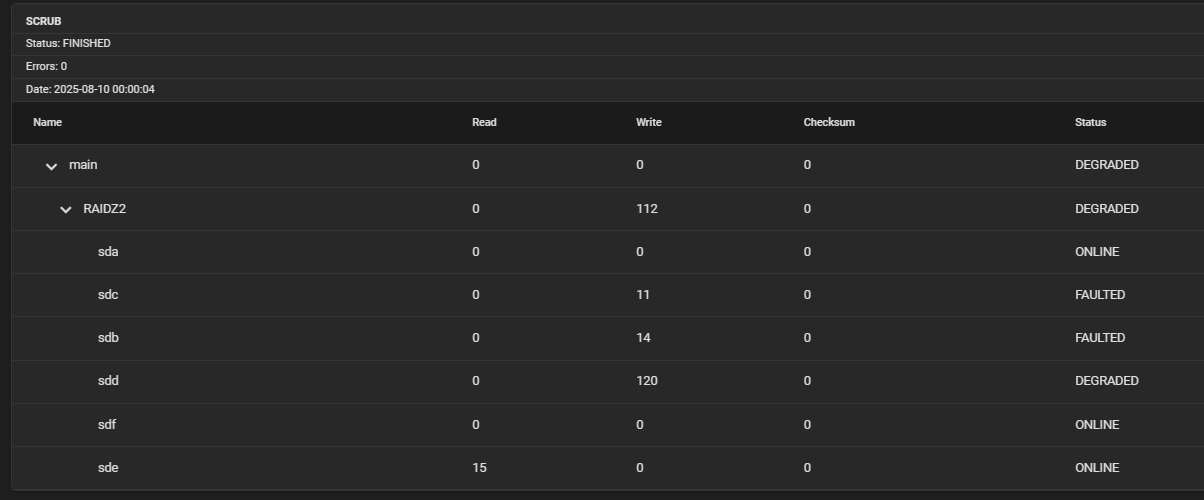
root@truenas[~]# zpool status -x
pool: main
state: DEGRADED
status: One or more devices are faulted in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Replace the faulted device, or use 'zpool clear' to mark the device
repaired.
scan: scrub repaired 0B in 12:13:36 with 0 errors on Sun Aug 10 12:13:40 2025
config:
NAME STATE READ WRITE CKSUM
main DEGRADED 0 0 0
raidz2-0 DEGRADED 0 64 0
5fbd08f9-1766-4a98-a925-6ec72e57c9b7 ONLINE 0 0 0
eddd497a-2a17-4881-8dc7-9e072502ca0d FAULTED 0 11 0 too many errors
635b948c-c99a-4050-89af-fc53976bc787 FAULTED 0 14 0 too many errors
fe62f7a9-2176-4951-a1b1-c076bd78a221 DEGRADED 0 66 0 too many errors
43907c64-a7b2-452d-a096-b7745fc9a43a ONLINE 0 0 0
34514601-4f4b-40e7-bc38-934d98408c77 ONLINE 15 0 0
errors: No known data errors
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 2 to 3.
2023-05-07 03:16:04 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 3 to 4.
2023-12-31 00:04:36 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 0 to 1.
2024-02-28 13:26:28 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 1 to 2.
2024-03-01 03:26:28 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 2 to 3.
2024-03-04 16:49:47 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 6 to 8.
2024-03-12 10:43:31 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], 8 Currently unreadable (pending) sectors.
2024-04-12 13:53:13 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 4 to 8.
2024-04-12 13:53:13 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], 32 Currently unreadable (pending) sectors.
2024-04-13 13:53:13 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 8 to 15.
2024-04-14 00:23:14 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 8 to 9.
2024-04-18 18:23:13 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 9 to 10.
2024-04-19 23:23:13 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 15 to 19.
2024-05-05 21:10:37 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 19 to 20.
2024-05-19 00:10:37 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 20 to 24.
2024-05-29 01:03:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sdd [SAT], ATA error count increased from 24 to 28.
2024-06-14 19:21:08 (Asia/Shanghai)
CRITICAL
Device: /dev/sdd [SAT], ATA error count increased from 28 to 29.
2024-06-23 00:21:08 (Asia/Shanghai)
CRITICAL
Device: /dev/sdd [SAT], ATA error count increased from 29 to 30.
2024-07-28 00:21:08 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], 24 Currently unreadable (pending) sectors.
2025-02-24 11:54:39 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 40 to 44.
2025-02-24 11:54:39 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 44 to 48.
2025-02-27 20:04:42 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 48 to 49.
2025-03-02 00:04:43 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 49 to 54.
2025-03-14 22:00:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 54 to 55.
2025-04-06 00:00:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 55 to 56.
2025-05-11 00:00:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 56 to 57.
2025-06-01 12:00:57 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 57 to 58.
2025-07-06 00:00:57 (Asia/Shanghai)
CRITICAL
Device: /dev/sdb [SAT], ATA error count increased from 0 to 1.
2025-08-06 13:30:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sdc [SAT], ATA error count increased from 11 to 12.
2025-08-07 10:00:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sde [SAT], ATA error count increased from 61 to 62.
2025-08-10 00:00:56 (Asia/Shanghai)
CRITICAL
Device: /dev/sdb [SAT], ATA error count increased from 2 to 4.
2025-08-10 20:00:57 (Asia/Shanghai)
My Questions:
- Are the ATA errors serious? Should I check my data cables or power supply connections?
- Should I replace the hard drives, use the
zpool clearcommand to ignore the errors, or perform some other operation to resolve the storage pool degradation? - I’m running an older version of TrueNAS. Should I upgrade to the latest version 25.04?
Any advice would be greatly appreciated. Thank you in advance for your help!