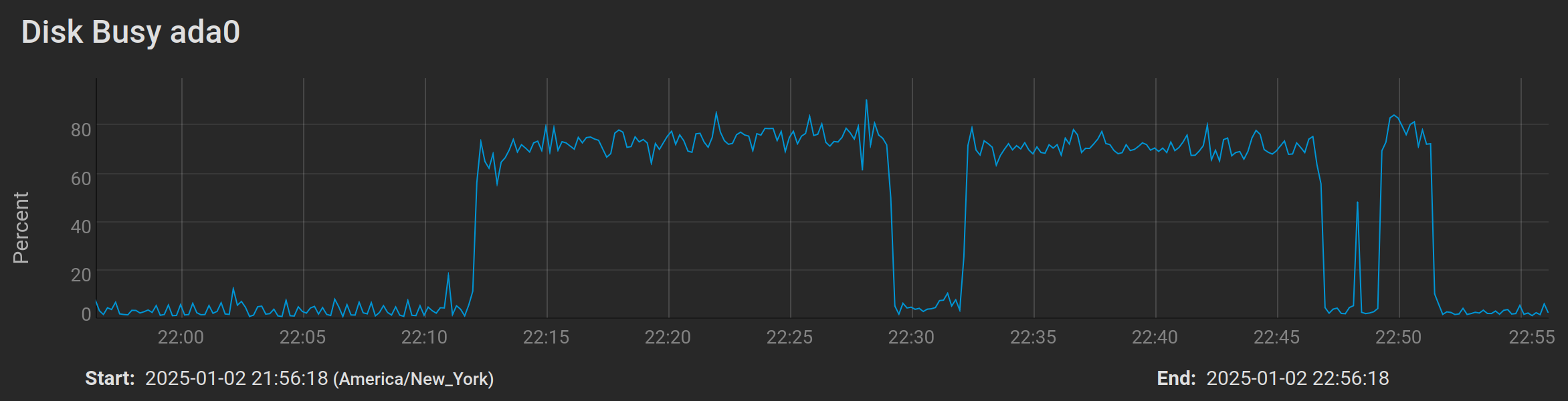
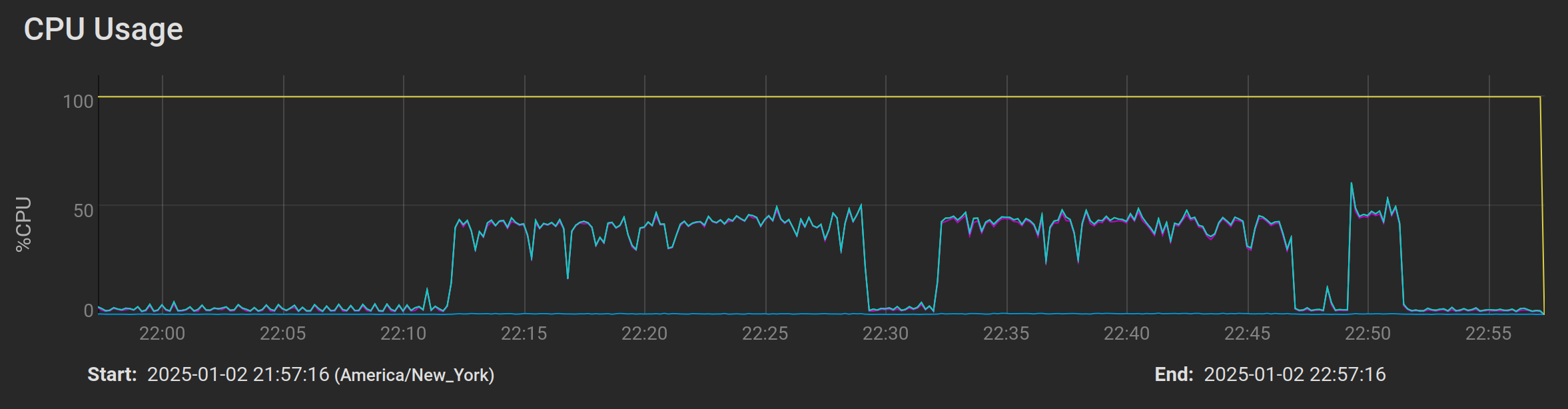
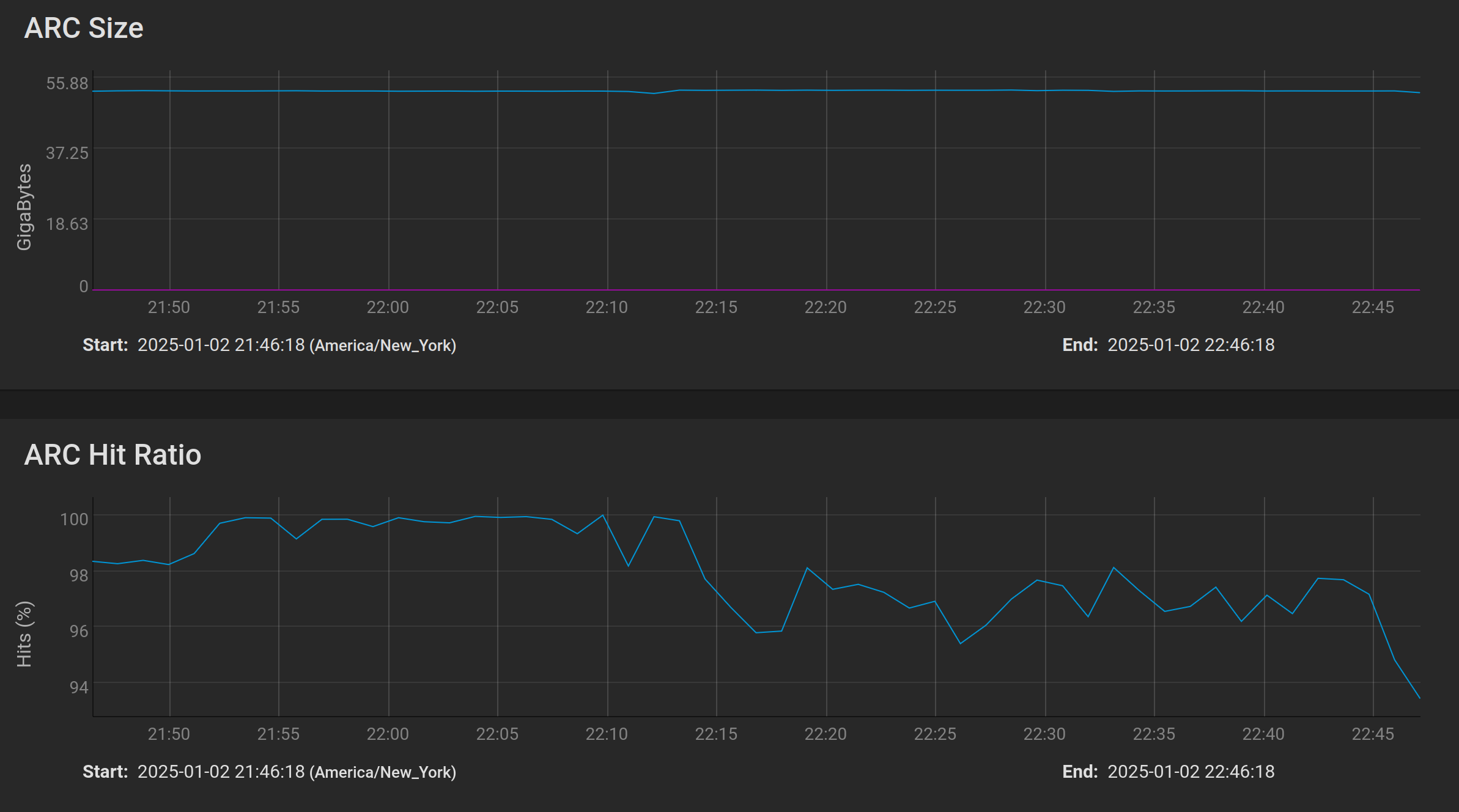
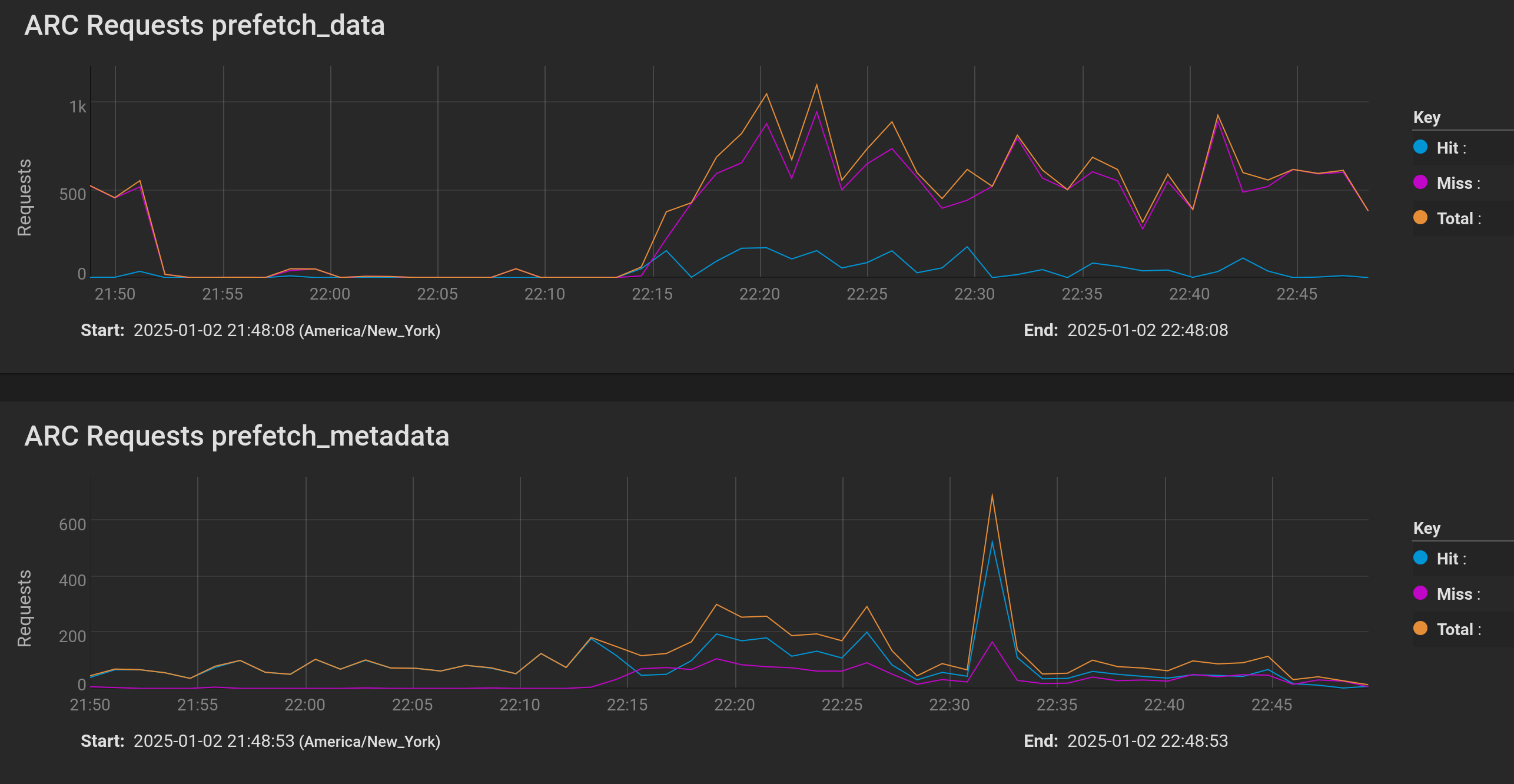
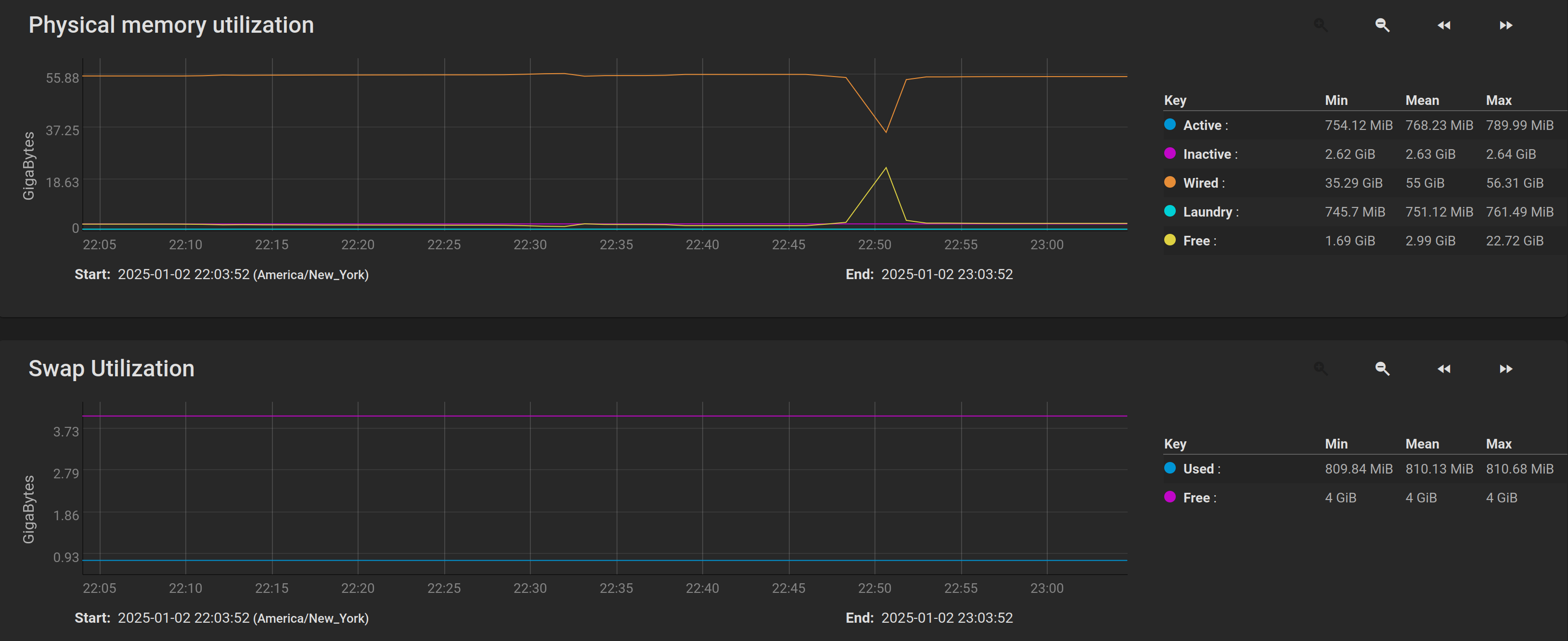
and here is the short 2-minute run
# fio --name TEST --eta-newline=5s --ioengine=posixaio --rw=write --size=150g --io_size=650g --blocksize=128k --iodepth=16 --numjobs=8 --runtime=120 --group_reporting
TEST: (g=0): rw=write, bs=(R) 128KiB-128KiB, (W) 128KiB-128KiB, (T) 128KiB-128KiB, ioengine=posixaio, iodepth=16
...
fio-3.28
Starting 8 processes
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
TEST: Laying out IO file (1 file / 153600MiB)
Jobs: 8 (f=8): [W(8)][5.8%][w=305MiB/s][w=2437 IOPS][eta 01m:53s]
Jobs: 8 (f=8): [W(8)][10.0%][w=325MiB/s][w=2599 IOPS][eta 01m:48s]
Jobs: 8 (f=8): [W(8)][15.0%][w=379MiB/s][w=3030 IOPS][eta 01m:42s]
Jobs: 8 (f=8): [W(8)][20.0%][w=252MiB/s][w=2018 IOPS][eta 01m:36s]
Jobs: 8 (f=8): [W(8)][25.0%][w=294MiB/s][w=2349 IOPS][eta 01m:30s]
Jobs: 8 (f=8): [W(8)][30.0%][w=333MiB/s][w=2660 IOPS][eta 01m:24s]
Jobs: 8 (f=8): [W(8)][35.0%][w=355MiB/s][w=2843 IOPS][eta 01m:18s]
Jobs: 8 (f=8): [W(8)][40.0%][w=301MiB/s][w=2409 IOPS][eta 01m:12s]
Jobs: 8 (f=8): [W(8)][45.0%][w=273MiB/s][w=2181 IOPS][eta 01m:06s]
Jobs: 8 (f=8): [W(8)][49.2%][w=306MiB/s][w=2445 IOPS][eta 01m:01s]
Jobs: 8 (f=8): [W(8)][53.3%][w=312MiB/s][w=2496 IOPS][eta 00m:56s]
Jobs: 8 (f=8): [W(8)][58.3%][w=312MiB/s][w=2499 IOPS][eta 00m:50s]
Jobs: 8 (f=8): [W(8)][63.3%][w=366MiB/s][w=2924 IOPS][eta 00m:44s]
Jobs: 8 (f=8): [W(8)][68.3%][w=355MiB/s][w=2840 IOPS][eta 00m:38s]
Jobs: 8 (f=8): [W(8)][72.5%][w=298MiB/s][w=2384 IOPS][eta 00m:33s]
Jobs: 8 (f=8): [W(8)][76.7%][w=334MiB/s][w=2673 IOPS][eta 00m:28s]
Jobs: 8 (f=8): [W(8)][81.7%][w=372MiB/s][w=2972 IOPS][eta 00m:22s]
Jobs: 8 (f=8): [W(8)][85.8%][w=319MiB/s][w=2550 IOPS][eta 00m:17s]
Jobs: 8 (f=8): [W(8)][90.8%][w=269MiB/s][w=2150 IOPS][eta 00m:11s]
Jobs: 8 (f=8): [W(8)][95.0%][w=381MiB/s][w=3051 IOPS][eta 00m:06s]
Jobs: 8 (f=8): [W(8)][100.0%][w=293MiB/s][w=2342 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=8): err= 0: pid=28963: Thu Jan 2 22:51:10 2025
write: IOPS=2887, BW=361MiB/s (378MB/s)(42.3GiB/120049msec); 0 zone resets
slat (usec): min=3, max=650093, avg=33.68, stdev=2127.44
clat (usec): min=10, max=654127, avg=44138.23, stdev=15499.71
lat (usec): min=49, max=654271, avg=44171.90, stdev=15602.61
clat percentiles (usec):
| 1.00th=[ 178], 5.00th=[ 1237], 10.00th=[ 38011], 20.00th=[ 40633],
| 30.00th=[ 41681], 40.00th=[ 43779], 50.00th=[ 45876], 60.00th=[ 47449],
| 70.00th=[ 49546], 80.00th=[ 52167], 90.00th=[ 55313], 95.00th=[ 59507],
| 99.00th=[ 69731], 99.50th=[ 76022], 99.90th=[139461], 99.95th=[185598],
| 99.99th=[337642]
bw ( KiB/s): min=210793, max=5100288, per=100.00%, avg=370128.81, stdev=55663.71, samples=1905
iops : min= 1642, max=39846, avg=2888.48, stdev=434.90, samples=1905
lat (usec) : 20=0.22%, 50=0.12%, 100=0.24%, 250=0.81%, 500=1.29%
lat (usec) : 750=0.96%, 1000=0.68%
lat (msec) : 2=1.59%, 4=0.35%, 10=0.37%, 20=0.53%, 50=64.87%
lat (msec) : 100=27.74%, 250=0.20%, 500=0.01%, 750=0.01%
cpu : usr=0.50%, sys=0.36%, ctx=256099, majf=0, minf=8
IO depths : 1=0.3%, 2=0.8%, 4=2.5%, 8=58.9%, 16=37.5%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=95.6%, 8=3.2%, 16=1.3%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,346596,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=16
Run status group 0 (all jobs):
WRITE: bw=361MiB/s (378MB/s), 361MiB/s-361MiB/s (378MB/s-378MB/s), io=42.3GiB (45.4GB), run=120049-120049msec