I’m curious as to why directory listing is so slow after I’ve had the machine off.
I’ve got 10x HDD,2 RZ1vdev, 20gb ram. SMB transfer is full gigabit 111MB/s and local dd speeds are 370MB/s
After a powerup/reboot, if I perform a ‘find -iname abcdefg’ in the root of my pool of ~50k files, it is very slow. And this is reflected in the browsing of my SMB shares and folders.
Once it is in RAM it is fine. I understand i could add an nvme persisting metadata L2ARC.
But I’m very curious as to why TrueNAS cant extract the data from my 10x HDD
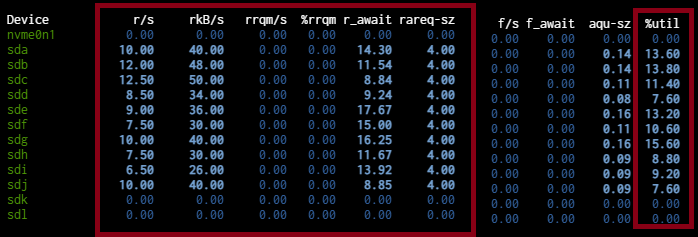
During this initial fresh-boot directory scan, in iostat -dx 2 i’ve got 5 to 15 iops per drive, showing a %util of ~%10 from each disk. Top shows me %87 idle, %12 wait.
How come my machine is half asleep yet im waiting for it to scan/list the directories?
When metadata remains in ARC (RAM), its speed is worlds faster than what can be pulled from spinning HDDs. There’s no way around that.
Every time you reboot, the RAM is cleared. The ARC must be repopulated with metadata.
A persistent L2ARC (“secondary ARC device”) can mitigate this.
Two questions:
Do you power-cycle your server that often where this becomes a problem?
Are you able to increase your total RAM? The presence of an L2ARC will require some additional ARC (in RAM) to track which blocks are in the L2ARC.
This could be due to measuring the aggregate of IOPS.
It’s like using a decibel meter to measure how loud certain sounds are. Even though clanking silverware is very loud (in terms of peak dB), some meters might result in much lower readings, due to not being able to give a precise measurement of the sharp peak that lasts only a fraction of a second.
Listing a directory is limited by IOPS; a vdev has the IOPS of a single drive, and HDD have poor IOPS performance. So your 10-wide raidz1 is working as hard as it can with small random seeks.
You reckon the dir listing is “Q1T1” ? And therefore waiting for each ~12ms, request, and therefore effectively grinding down to the speed of a single drive?
Very interesting. I wonder if I kicked off a few at the same time.
But they don’t. Aiui, metadata is a block. And parts of this block stored on the different disks of vdev (raidz in this case). So, to assemble this very block, each disk[1] must be queried.
Perhaps there is more complex algorithm as long as parity parts involved. ↩︎
In theory, all disks can be read at ~100iops all at the same time.
We can see that the zfs system is only reading one at a time - i.e send read req, wait, store the result, move on to the next “block-part” on the next disk, wait, store the result…
Didn’t get it. Each disk has 70 iops (if the waiting is 14 ms), because each disk is trying to find a part of the block. Thus, finding 70 blocks (I’m not so sure it works this way) per second.
Having 2 vdevs gives us 140 blocks per second. A directory with 140 files should show its content in ~1 second. A directory with 7000 files should show its content in 50 seconds.
Again, I’m very unsure about my “calculations”. Take them with a spoon of salt.
Yes the directory scan algorithm is clearly sequential - read, wait, read next block, wait. I have said that 5 times by now.
What I am curious about is why ZFS can’t parallelize this, when multiple directory scans are occurring at once, and the disks have plenty of idle time that could be serving reads…
If I understand it correctly, IOPS (in the HDD case) is something like how many “hops” the read-and-write head can make per second. Could the bigger queue value make the number of hops per second bigger? With some algorithmic tweaks — perhaps. But I don’t think it could scale linearly.
I’m talking about 10xHDDs, in 2xVdev. I am not saying that 4 jobs (Q1T4) could squeeze more IOPS out of a single drive.
I am wondering why 4 jobs cant squeeze more reads out of 10 HDDs.
We have already established that a single drive is ~14ms/70-120iops. I have also shown that the drives are 90% idle (i.e they have free time to server other reqs)