Hi all, I have a server that is showing the datapool is FAULTED. Luckily all the disks are showing back online. I have this setup in ProxMox as a VM. I’ve tried several commands “zpool import data -FXf, zpool import -f, etc”. I can’t get it to import. Anyone know how to fix this issue? See the screenshots. 16 disks total. Thanks!
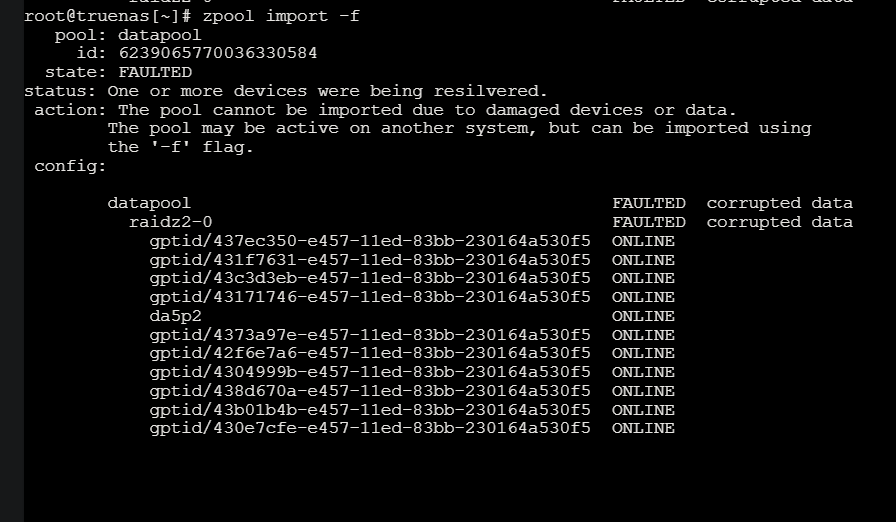
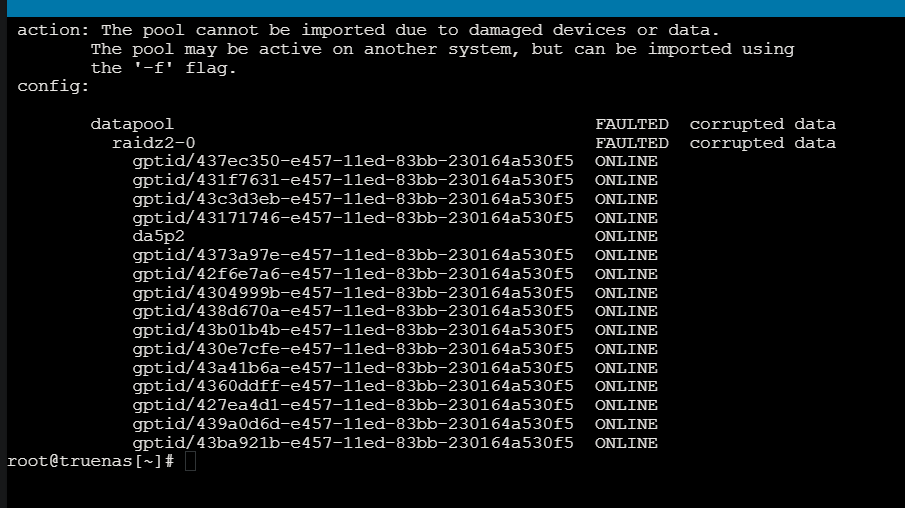
First off, if you had been using the ZFS pool in a VM, and did not have it configured correctly, it may be damaged. Even corrupted beyond repair.
Next, you import a pool with it’s name or ID, like this;
zpool import -f datapool
Without listing the pool’s name, the import option only lists pools that might be importable.
As for what could have corrupted your pool, using partitions in Proxmox and passing them through to the TrueNAS VM can do it. Other passing the whole disk to the VM.
The main method to insure reliable ZFS behavior in a VM is to pass the disk controller(s) that has ALL the disks to be used in the TrueNAS VM.
IIRC there is currently a bug / bad design decision in proxmox where it auto-imports zpools into the host OS. If the zpool is currently imported / in use in a guest as well this will cause pool corruption. ZFS is not a clustered filesystem and so it cannot be consumed by both host and guest simultaneously.
IIRC the only way to avoid the data corruption is HBA passthrough. @HoneyBadger has more details.
3 Likes
Hey @Gilfoyle - I remember trying to help out in Discord on this one. Guessing the pool is still unmountable?
Proxmox isn’t supposed to grab pools without the cachefile set to its own /etc/zfs/zpool.cache path (TrueNAS uses /data/zfs/zpool.cache) but Proxmox also appears to have a system service that will import pools on disk scan. So if there’s something that triggers a disk scan on a host and the member disks are visible this is likely to cause the simultaneous access/force-import bug. Isolating the disks via PCI passthrough of the HBA is the only way to guarantee that Proxmox can’t touch them once the TrueNAS VM is booted - but it may still attempt to grab the pool during Proxmox host boot unless the HBA is fully blacklisted from the host.
Setting systemctl disable --now zfs-import-scan.service on the host can disable this “import scan” behavior but it’s likely going to need some deeper investigation and soak-testing to determine when and where Proxmox might still try to grab the pool.
(Virtualizing TrueNAS on VMware isn’t impacted by this, because for better or worse, VMware doesn’t speak ZFS.)
5 Likes
@HoneyBadger Going back on this issue, is there an update on Proxmox behaviour?
And a possible fix for corrupted pools?
Re: behavior, I’m going to have to test it out a bit more extensively to figure out if there’s something specific that causes this to break. Proxmox as a host with a guest that uses non-IOMMU isolated disks is the prerequisite but it’s not an immediate “matter and antimatter” thing - it’s more like “fuel and oxygen are present, but something has to be the point of ignition”
Unfortunately, once a pool’s been corrupted by being simultaneously mounted by two different hosts, damage is usually irreperable - the options are basically limited to “try to import from an earlier, uncorrupted uberblock at an earlier transaction” - and without an already existing ZFS checkpoint that’s sometimes difficult or even impossible to do.
Some users have experienced varying degrees of success with Klennet recovery software, but this requires sufficient landing space to recover the data of course.
It seems to be worse than that, as there have been reports with a passed through HBA.
1 Like
I recall seeing that you should also blacklist the HBA in Proxmox to ensure the host can’t use it for any reason.
@HoneyBadger mentioned blacklisting above in addition to a systemctl. This makes quite a lot of requirements to virtualise TrueNAS in Proxmox… and not even being sure it is secure.
Should we make this thread a sticky, or create a sticky thread with detailed recomendations and instructions? Plus a big flashing red warning.
2 Likes
If that’s technically possible (and I think it is), maybe the warning should be integrated into TrueNAS itself. If the installer detects it is inside the Proxmox VM, it should give a big red flashing warning and demand signature in blood in triplicate, or outright refuse to install.
Well, there are reasons to still virtualize it. In my case, I virtualized Eel on Dragonfish so I can create my applications in the way I desire before I migrate to Eel, and test them. That wouldn’t be proxmox though, but, still, should be allowed. So, just saying should be allowed but yeah, maybe big warning.
There are literally thousands of times on reddit I see proxmox guys saying one should virtualize Truenas. Basically every day there’s at least one. And people believe them and go for it. If it works for some, great I guess, but, someone somewhere needs to warn them.
That particular report is also using three Seagate SMR drives, with one of them “making a strange tick” so I’m not quite ready to assign that to a double-mounted pool quite yet.
Still, one drive with a strange tick should not prevent from importing a raidz1 pool…
Another case, which you know of, also involves SMR drives.
And this one had a non-LSI HBA (Adaptec).
That makes for other suspects, but does not quite inspire trust in Proxmox.
If all you have is hammer…
Are there further reports of lost pools over there?
Yes, there’s been a few related to Proxmox, and a few related to power outages. I don’t have any handy links for them.
Hopefully that will have Proxmox developers (re)consider the scan-and-grab behaviour.
I doubt it sadly. So many posts pushing Proxmox with only the NAS in a VM.
Proxmox handling the storage with the SMB/NFS/iSCSI service in a VM? I don’t quite see how that would work.
If the issue is not fixed, Proxmox may be too dangerous an hypervisor for TrueNAS.
ESXi is dead for home use.
That leaves XCP-ng.
Or run TrueNAS bare metal and other services as sandboxes/VMs/containers.
“This is good for Bitcoin”, I guess.
1 Like
Any PCI-E device that PVE tries to use itself on boot will be a problem to be passed through to a VM.
For an HBA you just have to tell PVE to load the vfio-pci driver for that device and you are golden - PVE will not try to use it itself / import the disks.
This applies to GPUs as well where on PVE you need to make sure that it does not load the GPU driver on boot.
This is quite simple via the CLI - a GUI option would be nice but there is no indication that we will get that anytime soon. ![]()