Hey,
bclone explosion guy here.
I’ve been noticing some strange behaviors that as someone who just started using ZFS I don’t really understand.
First of all, the important specs:
Ryzen 5500G (6c/12t)
128GB DDR4
4x Toshiba MG09 18TB drives in RaidZ1 (LZ4 compression, 1MB allocation unit size)
10GbE TP-Link TX401 NIC
I tested three scenarios one after the other.
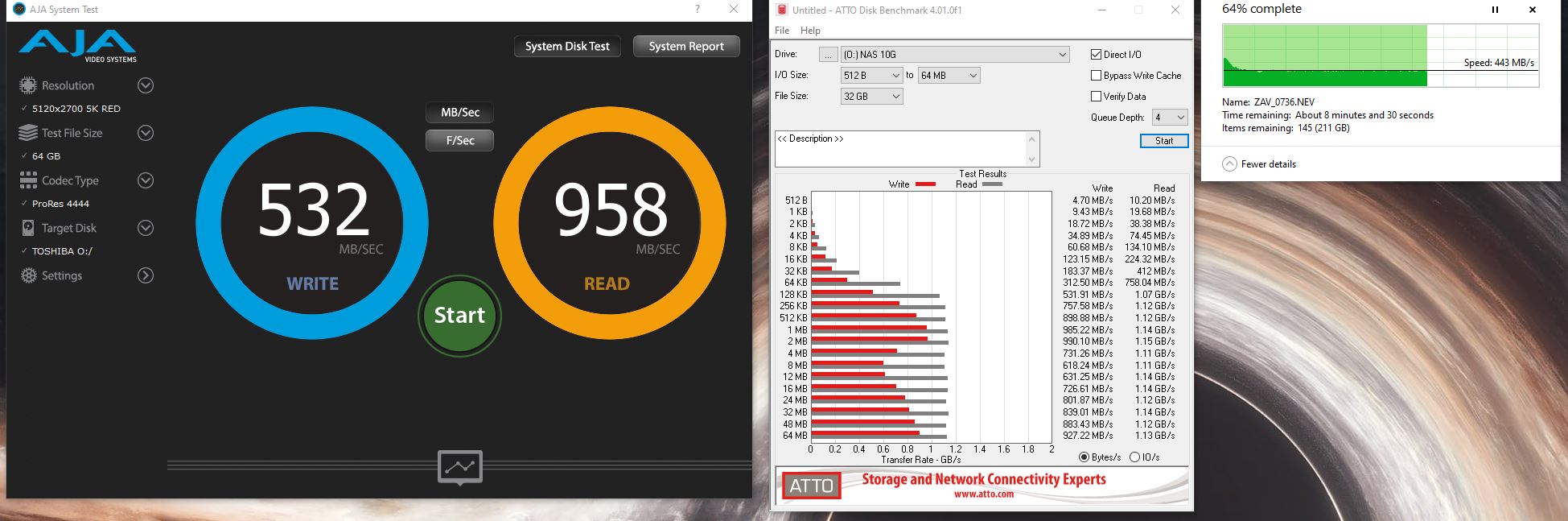
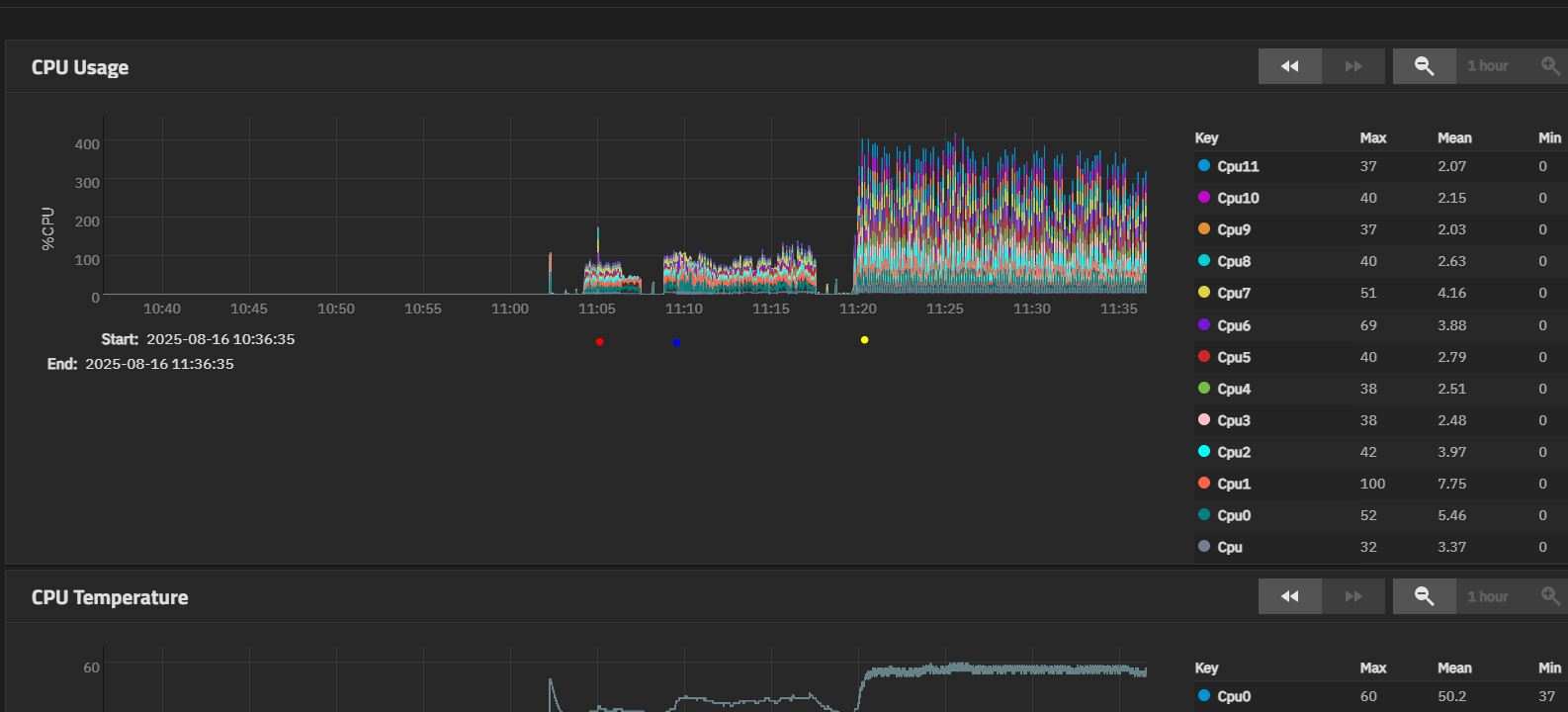
-AJA Video System Test (red dot under graph in dashboard screenshots), testing the R/W with a 64GB test file.
-ATTO Disk Benchmark (blue dot), testing with 32GB
-Simple write from W10 via SMB from a NVME drive (yellow dot).
PS, what are the spoiler tags on this forum so I can collapse the images below?

What I noticed:
-AJA System Test - Barely uses the CPU when compressing, and the drives are writing with about 3MB/s. Read speed reported from the drives in the test is almost nonexistent.
-ATTO Disk benchmark - A tad more CPU usage. Even smaller write speeds for the drives at about 0.3MB/s (they don’t even show up because the graph scaled with the transfer later on. Trust me, they’re above the blue dot)
-SMB Transfer - large video files. Stabilized at about 450-500MB/s after a few seconds at 1.1GB/s. Drives started writing with 250-270MB for those first few seconds, then plateaued at about 175MB/s. Which again seems a bit of a bottleneck somewhere as the pool is at 0% fragmentation and I’ve seen them hit 270MB/s sustained when reading. But just sometimes, it’s pretty inconsistent.
This brings me to my question.
I’m guessing the synthetic test data from the first two tests are just a bunch of ones or zeroes in repeating patterns and compression really works on them, and that’s why the write speed reported was so small.
(When testing the AJA System Test file size after it finished writing it, it was just a few MBs although it should have been 64GB.)
So the compression part worked as intended.
But why is the write speed still similar to the normal SMB transfer? Shouldn’t it have gone to the ethernet limits? I mean, if the CPU and the HDDs had absolutely no issue in compressing and writing that data(few MB of real disk space), shouldn’t it have maxed to 10GbE speeds? Especially considering that the 64GB should have easily fit into ARC, no matter what compression happened later? *ARC was empty, tests were ran just after a reboot.
Regarding the read speed, shouldn’t it have also be at 10GbE limits (~1230-1250MB/s), considering that the file that it had to read was only a few MB?
I didn’t run CrystalDiskMark, as that maxxes out the ethernet limits, most likely hitting ARC. (1233MB read / 800-900MB write for a 64GB test file) .But at least this shows the connection is not bottlenecked and can achieve max 10GbE speeds.
I’m not saying there’s an issue, I just want to understand what happens in the background.
P.S. Goldeneye says something that has me hyped, would this improve anything in cases similar to mine described above?
“OpenZFS acceleration: ARC and ZIL improvements, including DirectIO”