I have no idea how to best title this thread, because I have had SO many issues in the last 6 months that are very likely all related, so… I just tried to estimate which were the most important. (I am a total idiot as far as TrueNAS and have followed video tutorials for everything so far. I understand almost nothing, just doing my best). Hopefully this is resolved one way or another and helps someone else down the road. SO.
(For context, system info:
ASRock H670m ITX-ax motherboard
Intel Core i5-12600K CPU
Teamgroup T-Create 2x 16gb RAM
No GPU, integrated…
3x 4TB HDD’s in RAIDZ1, 2x are IronWolf NAS, one of which is the Pro version, 1x is the Skyhawk video recording drive.
TrueNAS Scale 25.10.1)
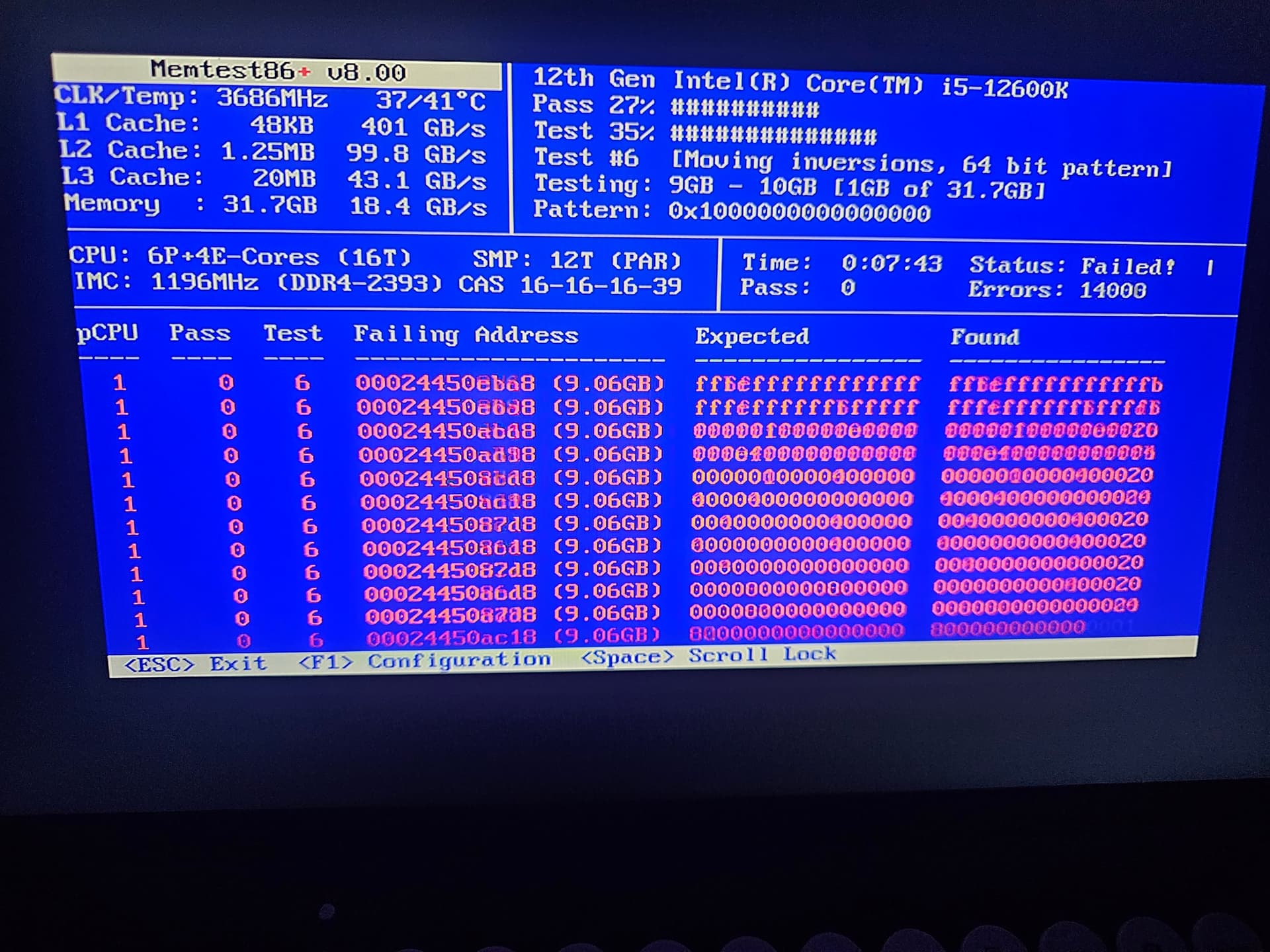
I have basically had CONSTANT checksum errors, ranging from 15-70 errors each month, per disk… almost perfectly equal numbers of errors across all 3 of my storage disks (it would usually be ~62 on two, maybe 63 on the third.. I would clear the errors ~monthly, and it would repeat. Now listen.. no matter WHAT I tried, no matter HOW many scrubs, how many resets, no matter what I did, I would still CONSTANTLY have my ZFS pool in the TrueNAS GUI showing as “unhealthy,” and I could never, ever figure out why, despite TrueNAS (AND the “Scrutiny” app telling me that ALL of my drives are perfectly healthy except for one failing a minor test, I don’t remember which..) At best, I had ~13 checksum errors per disk in a month). My searching led me to believe this is usually an issue with cabling or my storage controller chip on my motherboard. Well, I didn’t have money to replace it so I just unplugged/re-seated my HDD cables 3 times, kept scrubbing, making backups, and crossing fingers.
About two months(?) ago I had an issue where I couldn’t log in to my server, and had to re-install TrueNAS, I have a post about it: here
Basically, got a “kernel panic” error at boot and had to re-install TrueNAS.
NOW… just this week, again, smart devices not working, Jellyfin server unresponsive, so I log into my server GUI.. Guess what? I can log into it just fine, but I check my storage pool and it says it detects 3 drives that were.. IIRC.. “exported to another pool”? I am trying to find the exact error message in my Google photos but I can’t, so I don’t remember exactly what the message was. Point is, I tried to import the pool, but it would not show up on the drop down menu in the GUI. It was just blank when I went to the “import pool” button…
So, I tried to do it manually, as I said, via the following comand, which I got from Google Gemini by asking the stupid AI for help: "sudo zpool import -f -R /mnt/ (“Pool Name”)”
And in response, I got the error message:
”cannot import ‘JacobsNAS’: I/O error
Destroy and re-create the pool from a backup source.”
So.. my memory is hazy and I am not certain this is exactly right, but I believe my next move was to use the actual Pool ID number with the same command.. so I tried, IIRC:
”bash
sudo zpool import -f -R /mnt/ (pool partition ID#)”
Again, at the recommendation of Google Gemini AI, and THIS time.. I got a frozen screen, for an hour. I then tried to log into the server GUI again, and couldn’t. At all. So.. I plugged in my portable monitor, mouse and keyboard to the server, and THIS is what I saw on the screen:
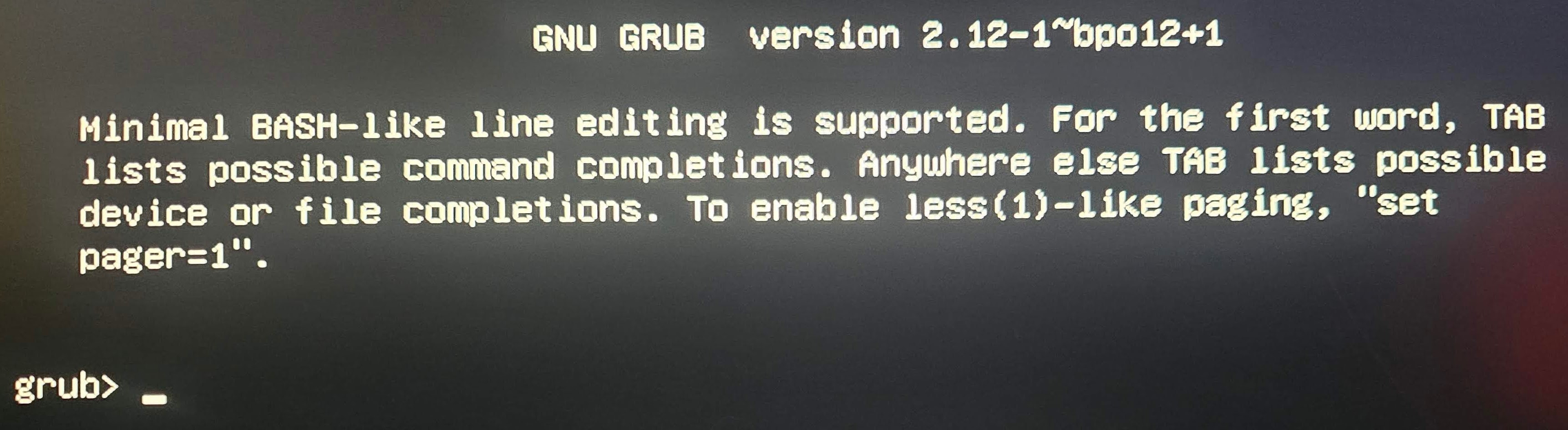
I have no idea what I was looking at here.
Now, I’m trying to re-install TrueNAS Scale 25.10.1 yet again because, idk what else to do, and I’m getting these errors..

Which my searching indicates implies an issue with my USB installation media, or with my mobo’s USB controller. So. I am re-flashing my USB intallation media (old flash drive) and hoping that it will help, if no I will try a micro SD card in a USB adapter.
(BTW, I just accidentally ruined an SD card with photos from the 5 day trip my partner and I took to see the total solar eclipse in 2024, including eclipse photos that I cared a lot about, because I rushed through the Balena Etcher menus out of frustration.. and now I’m even more frustrated, obviously ![]() )
)
But. I was hoping that all of this info might lead someone smarter than me to an idea for an underlying problem.. considering that I’ve had nearly constant issues with this server, I am betting that my motherboard or some other hardware aside from my HDD’s is bad… but I need advice for sure, to help figure that out. Please ![]() Thank you SOOO much…
Thank you SOOO much…
**EDIT**: I have tried reformatting and re-installing the TrueNAS installation .iso to the same USB drive, which gave the same errors as shown above, and then, on my only spare USB device (a brand new micro SD card in a USB adapter), which also gave the same exact errors (“cannot enumerate USB device”) Soooooo…. at a loss here. Do I need to buy a new mobo?