Hi everybody,
I am seeking for your help because I think my copy of a large number of files is taking too long
So my goal was to copy my Nextcloud data directory from /mnt/data/rancher/ncfpm/(back from Rancher/ VM/ FreeNAS days) to /mnt/data/apps/nextcloud/data/ using this command:
rsync -rl --no-i-r --info=progress2 --chown=nextcloud:nextcloud --stats /mnt/data/rancher/ncfpm/ /mnt/data/apps/nextcloud/data/
The old rancherdataset was unencrypted and contained data for multiple service.
I wanted to split datasets between services and add encryption (the new dataset is encrypted).
Furthermore, I added the chown flag to adjust the file permission.
I did a dry run before to see what am I expecting:
Number of files: 2,550,196 (reg: 1,692,349, dir: 857,685, link: 162)
Number of created files: 2,550,031 (reg: 1,692,347, dir: 857,684)
Number of deleted files: 0
Number of regular files transferred: 1,692,349
Total file size: 1,213,261,475,251 bytes
Total transferred file size: 1,213,261,467,599 bytes
Literal data: 0 bytes
Matched data: 0 bytes
File list size: 196,574
File list generation time: 0.001 seconds
File list transfer time: 0.000 seconds
Total bytes sent: 74,513,073
Total bytes received: 8,542,911
sent 74,513,073 bytes received 8,542,911 bytes 559,299.56 bytes/sec
total size is 1,213,261,475,251 speedup is 14,607.76 (DRY RUN)
Quite a lot of small files (I guess generated image previews) and a total of around 1.2TB of data.
My pool is a RAIDZ with 4 TB SSDs ( VULCAN Z SSD 4TB - TEAMGROUP )
Nothing fancy, but should be doable in a night, I thought…
When I turned on my PC this morning after around 10 hours of transfer, this was the status:
root@truenas:/mnt/data/apps/nextcloud/data# rsync -rl --no-i-r --info=progress2 --chown=nextcloud:nextcloud --stats /mnt/data/rancher/ncfpm/ /mnt/data/apps/nextcloud/data/
622,807,065,469 51% 9.28MB/s 17:46:40 (xfr#1325000, to-chk=523135/2550196)
So I came to around 622 GB, but the transfer speed has decreased significantly.
It started with around 60 MB/s and then went down to 30 MB/s quite quickly.
But now I can see the individual megabytes increasing just every minute. At this rate I guess this will never finish.
So I stopped all VMs that were still running, disabled any shares and rebooted the system.
Even after rebooting, the TrueNAS UI is very slow compared to what it was before.
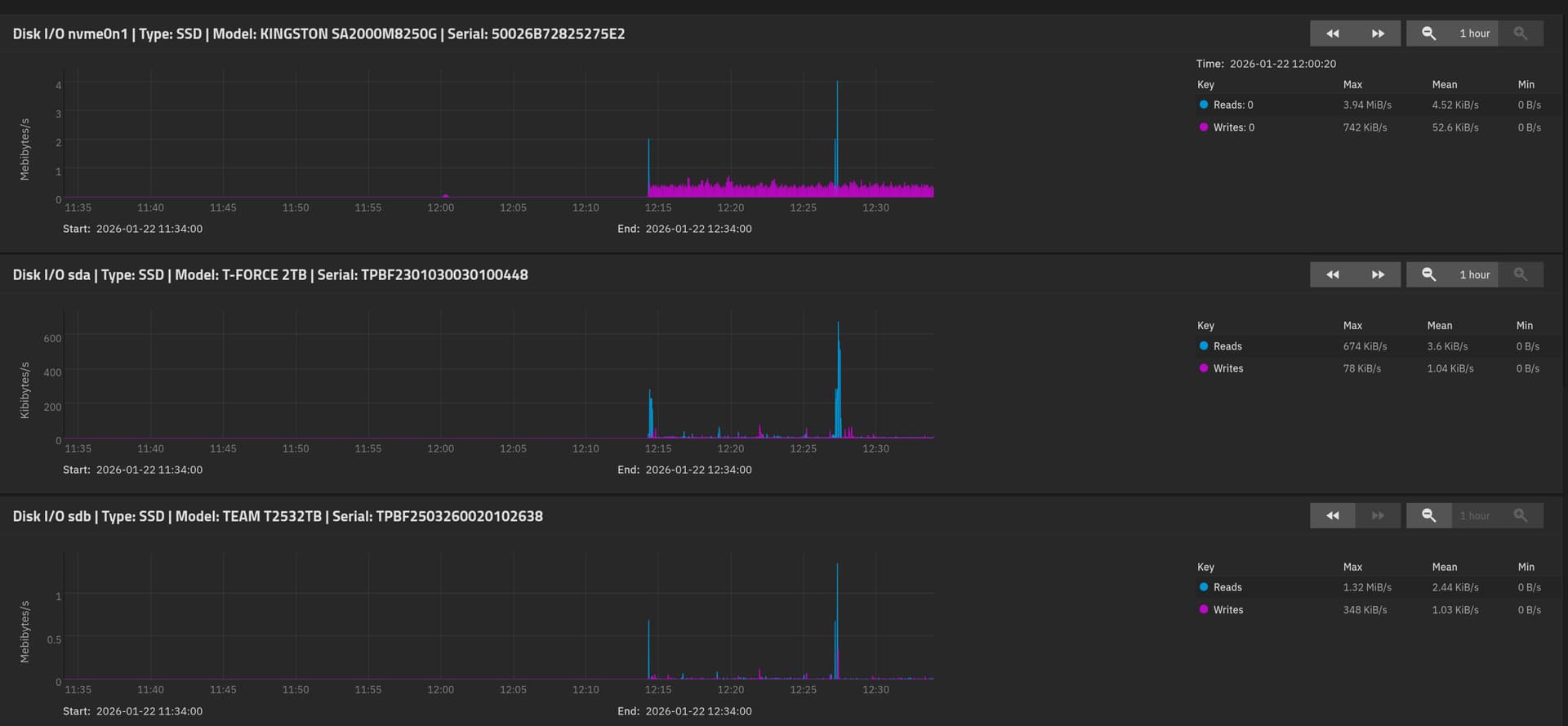
Reports don’t load at all or just incomplete (from what I remember) like this ZFS report:

The disk report shows very little load on the disks (first one is from boot pool, the next from the data pool).
I cannot zoom out for more than 1 hour, unfortunately, because it just doesn’t show any data then.
I tried to restart the rsync command, but now it’s not showing any progress at all.
I suppose it is still waiting on the directory traversal completion, something that took a few minutes yesterday, but now I guess the system’s performance is just very slow.
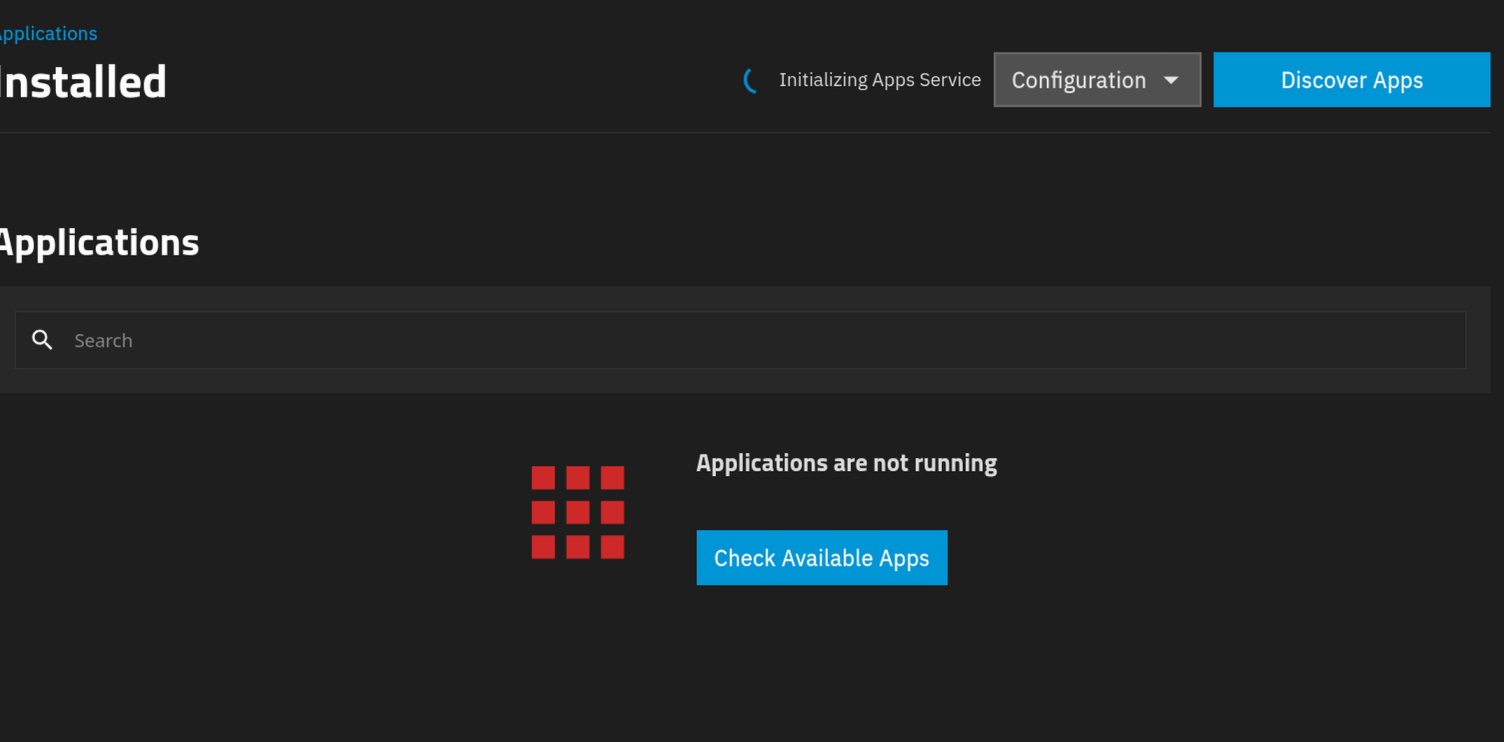
The apps page is stuck on “Initializing apps service” and the Docker daemon doesn’t load anymore.
Any ideas what is going on with my system?
I am using a AMD Ryzen 5 5600 6-Core Processor with 32 GB ECC RAM.
My data pool has still 1.8 TiB free space.
I downloaded debug logs, if those are relevant here…?
Edit: Htop shows no significant load and plenty of memory left: