smartctl --scan-open
/dev/sda -d sat # /dev/sda [SAT], ATA device
/dev/sdb -d sat # /dev/sdb [SAT], ATA device
/dev/sdc -d sat # /dev/sdc [SAT], ATA device
/dev/sdd -d sat # /dev/sdd [SAT], ATA device
# /dev/sde -d scsi # /dev/sde, SCSI device open failed: INQUIRY failed
/dev/sdf -d sat # /dev/sdf [SAT], ATA device
/dev/nvme0 -d nvme # /dev/nvme0, NVMe device
note - unplugging and re-plugging seems to have changed the sdN assignments. the misbehaving drive is still sde, but the working boot drive is now sdd instead of sdf.
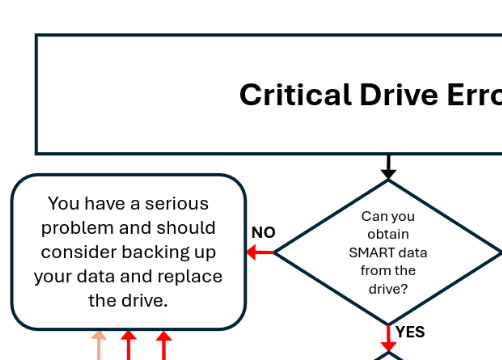
sde shows as scsi, which is seems odd when all of the other sata drives show as ata. but anyway, smartctl -d scsi -x /dev/sde doesn’t get me anything helpful.
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.6.44-production+truenas] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
Standard Inquiry (36 bytes) failed [Input/output error]
Retrying with a 64 byte Standard Inquiry
Standard Inquiry (64 bytes) failed [Input/output error]
A mandatory SMART command failed: exiting. To continue, add one or more '-T permissive' options.
midclt call disk.smart_attributes sde | jq > sde.txt also says fails at the top, but it has a lot of detail after that
EFAULT] smartctl failed for disk sde:
{
"json_format_version": [
1,
0
],
"smartctl": {
"version": [
7,
4
],
"pre_release": false,
"svn_revision": "5530",
"platform_info": "x86_64-linux-6.6.44-production+truenas",
"build_info": "(local build)",
"argv": [
"smartctl",
"-A",
"/dev/sde",
"-j"
],
"messages": [
{
"string": "Smartctl open device: /dev/sde failed: INQUIRY failed",
"severity": "error"
}
],
"exit_status": 2
},
"local_time": {
"time_t": 1741097294,
"asctime": "Tue Mar 4 08:08:14 2025 CST"
}
}
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 211, in call_method
result = await self.middleware.call_with_audit(message['method'], serviceobj, methodobj, params, self)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1529, in call_with_audit
result = await self._call(method, serviceobj, methodobj, params, app=app,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1460, in _call
return await methodobj(*prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 179, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 49, in nf
res = await f(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/disk_/smart_attributes.py", line 41, in smart_attributes
output = json.loads(await self.middleware.call('disk.smartctl', name, ['-A', '-j']))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1629, in call
return await self._call(
^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/main.py", line 1460, in _call
return await methodobj(*prepared_call.args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/schema/processor.py", line 179, in nf
return await func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3/dist-packages/middlewared/plugins/disk_/smartctl.py", line 75, in smartctl
raise CallError(f'smartctl failed for disk {disk}:\n{cp.stdout}')
middlewared.service_exception.CallError: [EFAULT] smartctl failed for disk sde:
{
"json_format_version": [
1,
0
],
"smartctl": {
"version": [
7,
4
],
"pre_release": false,
"svn_revision": "5530",
"platform_info": "x86_64-linux-6.6.44-production+truenas",
"build_info": "(local build)",
"argv": [
"smartctl",
"-A",
"/dev/sde",
"-j"
],
"messages": [
{
"string": "Smartctl open device: /dev/sde failed: INQUIRY failed",
"severity": "error"
}
],
"exit_status": 2
},
"local_time": {
"time_t": 1741097294,
"asctime": "Tue Mar 4 08:08:14 2025 CST"
}
}```